Executive Summary
- Projection of AMD MI430X performance based on SC25 data, targeting a major leap in FP64 (double-precision) compute.
- Analysis of the 3nm-class CDNA architecture and its integration into the “Discovery” exascale system.
- Strategic assessment of AMD’s focus on high-precision scientific computing as a counter-move to Nvidia’s AI-centric focus.
Strategic Deep-Dive
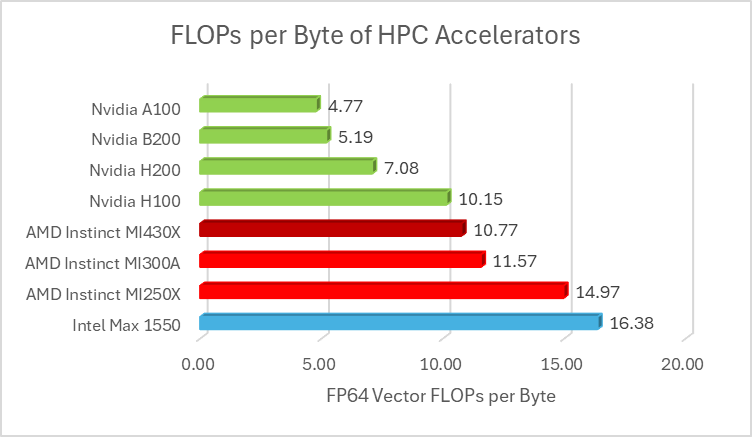
The upcoming AMD Instinct MI430X represents a calculated strike by AMD to reclaim its dominance in the High-Performance Computing (HPC) and supercomputing sectors. While much of the industry has pivoted toward low-precision AI formats (FP8/FP4), the data presented at SC25 suggests that the MI430X will set a new benchmark in FP64 (double-precision) performance. This is critical for traditional scientific simulations—such as fluid dynamics, nuclear physics, and climate modeling—where numerical stability and precision are non-negotiable.
Building upon the MI300X, which already achieved 163.7 TFLOPS of peak FP64 performance, the MI430X is projected to leverage a refined 3nm-class process and a more dense CDNA architecture to push these figures significantly higher, potentially targeting a 1.5x to 2x generational uplift in compute density.
The “Discovery” supercomputer serves as the primary deployment vehicle for the MI430X. Unlike general-purpose cloud clusters, Discovery is designed to tackle the most demanding scientific challenges, requiring massive memory bandwidth and low-latency interconnects. The MI430X addresses these needs through the integration of HBM3e memory, which not only increases capacity but also enhances the sustained throughput required for memory-bound HPC codes.
AMD’s chiplet-based strategy allows them to mix and match compute and memory tiles, optimizing for yields while delivering the massive TFLOPS per watt metrics required by national laboratories facing stringent power envelopes.
From a strategic perspective, AMD is positioning the Instinct line as the “Big Iron” alternative to Nvidia’s Blackwell. While Nvidia’s recent architectures have leaned heavily into AI-specific features like the Transformer Engine, AMD remains committed to the high-precision requirements of the HPC community. This commitment is bolstered by the maturation of the ROCm 6.x software stack, which has seen significant improvements in compiler efficiency and library support for OpenMP and MPI.
By offering superior raw FP64 performance at a potentially lower TCO than Nvidia’s equivalent solutions, AMD is securing its place as the preferred vendor for next-generation exascale projects. The success of the MI430X on the Discovery system will be a litmus test for whether AMD can maintain its momentum and challenge the market leader not just in hardware specs, but in reliable, large-scale scientific execution.

