Executive Summary
- Technical analysis of Uniform Memory Access (UMA) vs. Nodes Per Socket (NPS) modes on AMD’s Turin (Zen 5) EPYC CPUs.
- Investigation into the latency penalties of the I/O Die (IOD) and CCD interconnects observed by Verda.
- Strategic insights into the future of server CPU design as core counts exceed 128 per socket.
Strategic Deep-Dive
As server architectures scale toward extreme core densities, the physical layout of the silicon increasingly dictates software performance. AMD’s Turin platform, the latest evolution of the EPYC line based on the Zen 5 architecture, presents a complex challenge regarding memory topology. Traditionally, operating systems prefer a Uniform Memory Access (UMA) model, where every CPU core sees the entire system memory as a single pool with identical latency.
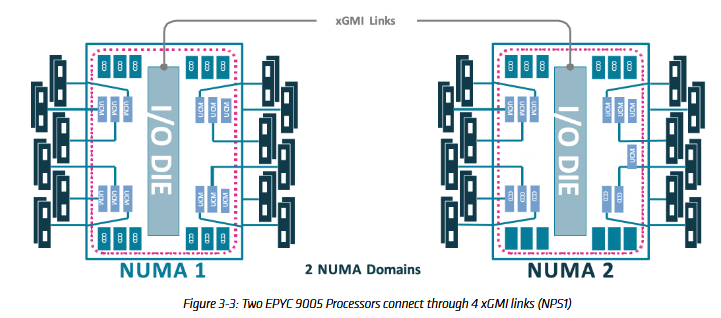
However, as Verda (formerly DataCrunch.io) has recently evaluated, the underlying hardware of Turin is anything but uniform. The architecture consists of multiple Core Complex Dies (CCDs) connected to a central I/O Die (IOD) via AMD’s Infinity Fabric. This physical reality creates “hops” that inevitably introduce non-uniform latency, ranging from local L3 cache access to cross-die memory controller requests.
Verda’s testing of the Turin platform highlights the significant trade-offs involved in selecting the right memory interleaving mode. In UMA mode, the hardware abstracts the underlying complexity to provide a simplified view to the OS scheduler. While this improves compatibility with legacy applications that are not “NUMA-aware,” it often results in an average latency penalty.
For instance, a core on a peripheral CCD might experience significantly higher nanosecond counts when accessing memory controlled by an IOD channel on the opposite side of the socket. To mitigate this, Turin supports various Nodes Per Socket (NPS) modes. NPS1, NPS2, or NPS4 modes partition the memory into smaller, more localized domains that align with the physical die layout.
Verda’s benchmarks indicate that for high-bandwidth workloads like database indexing or fluid simulations, switching to NPS4 can yield double-digit performance gains by ensuring that data stays as close to the processing core as possible.
The broader implication for senior infrastructure engineers is that the era of “set-and-forget” BIOS settings is over. As core counts scale beyond 128 and 192 cores per socket, the L3 cache distribution (typically 32MB per CCD) and the interconnect fabric’s congestion control become the primary bottlenecks. The Turin evaluation proves that modern server design is a game of managing “micro-latencies.” For cloud providers like Verda, optimizing the BIOS-level memory interleave settings is now as crucial as the CPU selection itself.
Moving forward, we expect to see more “topology-aware” schedulers in Linux and other kernels that can dynamically adjust to these complex internal landscapes, but for now, the burden of performance tuning remains with the specialized infrastructure analyst who understands the silicon’s internal topography.


