Executive Summary
- Google has announced its eighth generation of custom Tensor Processor Units (TPUs) at Google Cloud Next, signaling a shift toward a dual-path architectural strategy. By splitting the generation into the TPU 8t (Training) and TPU 8i (Inference), Google aims to optimize the entire AI lifecycle for the next decade of agent-based supercomputing.
Strategic Deep-Dive
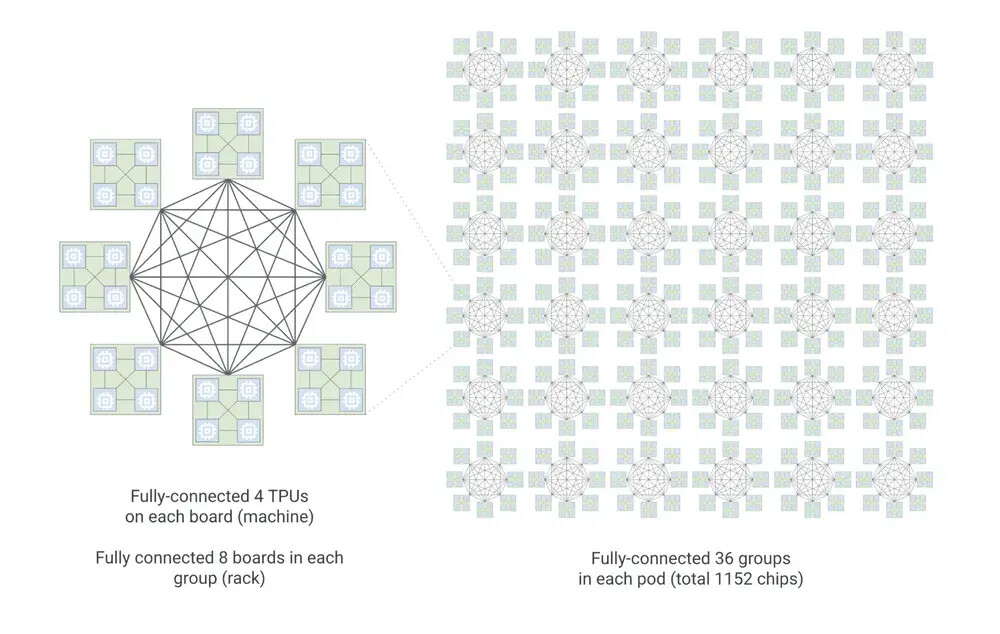
At the latest Google Cloud Next, the unveiling of the 8th Gen TPU represented more than just a performance increment; it was a declaration of architectural independence. The decision to bifurcate the lineup into the TPU 8t (Training) and TPU 8i (Inference) addresses the diverging hardware requirements of the modern AI era. Training large-scale foundational models, which now frequently exceed a trillion parameters, demands massive computational “muscle” and extensive high-bandwidth memory (HBM).
The TPU 8t is specifically engineered for this, focusing on peak Matrix Multiplication Unit (MXU) performance and an industry-leading interconnect fabric that allows thousands of nodes to function as a single unified supercomputer.
Conversely, the TPU 8i is the scalpels to the 8t’s sledgehammer. Once a model is trained, the challenge shifts to “massive inference workloads”—serving millions of simultaneous requests with minimal latency and maximum energy efficiency. The TPU 8i is optimized for throughput-per-watt, likely utilizing advanced quantization techniques (such as FP8 or INT8) to accelerate inference cycles without the thermal or power overhead of a training-grade chip.
This dual-path approach allows Google to build “custom-built supercomputers” that are perfectly balanced for the specific stage of the AI pipeline they are intended to serve.
From a systems architecture standpoint, the most critical aspect of the 8th Gen TPU is the interconnect technology. Google has been a pioneer in Optical Circuit Switching (OCS), and the TPU 8t likely leverages even more advanced optical fabrics to eliminate the “tail latency” that can cripple large-scale model training. By moving away from traditional copper interconnects, Google can scale its AI clusters to unprecedented levels, providing the backbone for “agent development”—AI systems that don’t just respond to prompts but actively execute multi-step workflows across the cloud.
This vertical integration allows Google to bypass the supply chain bottlenecks and high margins associated with third-party GPU vendors like NVIDIA. By owning the silicon for both training and inference, Google can optimize its software stack (XLA and JAX) to a degree that general-purpose hardware cannot match. As we enter an era where AI agents become ubiquitous, this hardware-independent strategy ensures that Google Cloud remains the premier destination for high-efficiency, large-scale AI deployment.


