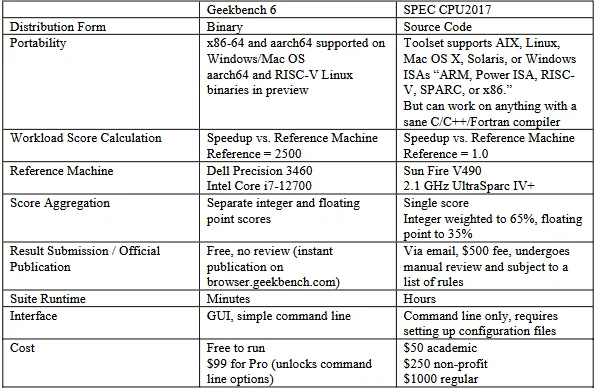
🔍 Executive Summary
- As hardware architectures shift toward heterogeneous computing and specialized AI silicon, single-score benchmarks like Geekbench 6 struggle to capture the nuanced performance realities of modern, diverse application demands.
Strategic Deep-Dive
The release of Geekbench 6 has reignited a critical debate among data systems architects and hardware enthusiasts: can a cross-platform synthetic benchmark truly encapsulate the performance profile of a modern computing system? In an era where silicon is increasingly specialized, the pursuit of a single ‘hero number’ to define a device’s worth is becoming an obsolete practice. The fundamental issue lies in the radical variance of application demands.
Software today is not a monolithic block of instructions; it is a complex orchestration of tasks that exercise specific hardware subsystems, from the traditional Arithmetic Logic Units (ALUs) to the burgeoning Neural Processing Units (NPUs) designed for artificial intelligence.
From an architectural perspective, the limitations of Geekbench 6 start with its approach to Instruction-Level Parallelism (ILP) and branch prediction. Modern CPUs are incredibly sophisticated at predicting the next move of a program, but synthetic benchmarks often use predictable code paths that don’t reflect the ‘spiky’ and unpredictable nature of real-world applications. When a developer runs a complex database engine or a large-scale software compilation, the system frequently encounters memory hierarchy bottlenecks.
A benchmark with a small memory footprint might reside entirely within the L3 cache, producing stellar results that vanish once the system is hit with a real workload that misses the cache and forces high-latency requests to main memory. The nuances of cache-coherent interconnects in modern chiplet-based designs—such as those seen in AMD’s Zen architectures or Apple’s Ultra series—are often lost in these simplified scoring models.
Furthermore, we must address the ‘NPU Paradox.’ As System-on-Chip (SoC) vendors integrate more AI-specific silicon to handle tasks like Gaussian blur, image recognition, and real-time encryption, the standard benchmark tests often continue to route these tasks through the CPU’s vector units. This results in a double failure: it fails to measure the actual performance the user would experience via the hardware accelerator, and it misrepresents the power efficiency of the system. If a benchmark doesn’t trigger the specialized silicon that makes a modern iPhone or Snapdragon chip efficient, it provides a data point that is technically accurate but practically irrelevant.
For example, machine learning workloads that thrive on low-precision math (INT8/FP16) may show mediocre CPU results while the underlying NPU is capable of orders-of-magnitude better throughput.
Moreover, the weighting of subtests in Geekbench 6 highlights the difficulty of representative scoring. Determining whether a PDF rendering test should carry more weight than a photo-tagging simulation is inherently subjective and often divorced from individual user realities. A developer, a video editor, and a casual social media user have three entirely different performance requirements.
By averaging these disparate demands into a single integer, we lose the ‘granularity of performance’ that is essential for informed hardware selection. We are seeing a trend where manufacturers optimize their silicon for the specific patterns used in benchmarks—a phenomenon known as ‘benchmark optimization’—which can lead to performance regressions in non-benchmarked areas.
To move forward, the industry must transition from single-score abstractions to multidimensional performance profiles. As systems architects, we need to see how a device handles sustained throughput versus bursty latency-sensitive tasks. We need to understand the interaction between the memory controller and specialized accelerators.
The ‘one-size-fits-all’ benchmarking philosophy is a relic of the general-purpose compute era. In the age of heterogeneous computing, our evaluation frameworks must be as sophisticated and diverse as the silicon they aim to measure.
