핵심 요약
- 구글은 Google Cloud Next 2026에서 자사 커스텀 AI 가속기의 정점인 8세대 TPU를 전격 공개했습니다. 이번 세대의 핵심 혁신은 하드웨어 설계를 ‘학습용(TPU 8t)‘과 ‘추론용(TPU 8i)‘으로 완전히 이원화한 ‘듀얼 패스(Dual-Path)’ 전략에 있습니다. TPU 8t는 조 단위 파라미터를 가진 거대 언어 모델(LLM)과 차세대 AI 에이전트 학습을 위해 극대화된 행렬 연산 능력과 초고대역폭 메모리(HBM)를 탑재했습니다. 반면, TPU 8i는 서비스 단계에서의 에너지 효율과 처리량(Throughput)에 최적화되어, 대규모 사용자 요청을 실시간으로 처리하는 데 특화된 저전력·고성능 구조를 지니고 있습니다.
상세 분석
목적별 특화 설계: TPU 8t와 8i 아키텍처
구글은 Google Cloud Next 2026에서 자사 커스텀 AI 가속기의 정점인 8세대 TPU를 전격 공개했습니다. 이번 세대의 핵심 혁신은 하드웨어 설계를 ‘학습용(TPU 8t)‘과 ‘추론용(TPU 8i)‘으로 완전히 이원화한 ‘듀얼 패스(Dual-Path)’ 전략에 있습니다. TPU 8t는 조 단위 파라미터를 가진 거대 언어 모델(LLM)과 차세대 AI 에이전트 학습을 위해 극대화된 행렬 연산 능력과 초고대역폭 메모리(HBM)를 탑재했습니다.
반면, TPU 8i는 서비스 단계에서의 에너지 효율과 처리량(Throughput)에 최적화되어, 대규모 사용자 요청을 실시간으로 처리하는 데 특화된 저전력·고성능 구조를 지니고 있습니다.
AI 에이전트 및 대규모 모델 최적화와 슈퍼컴퓨팅
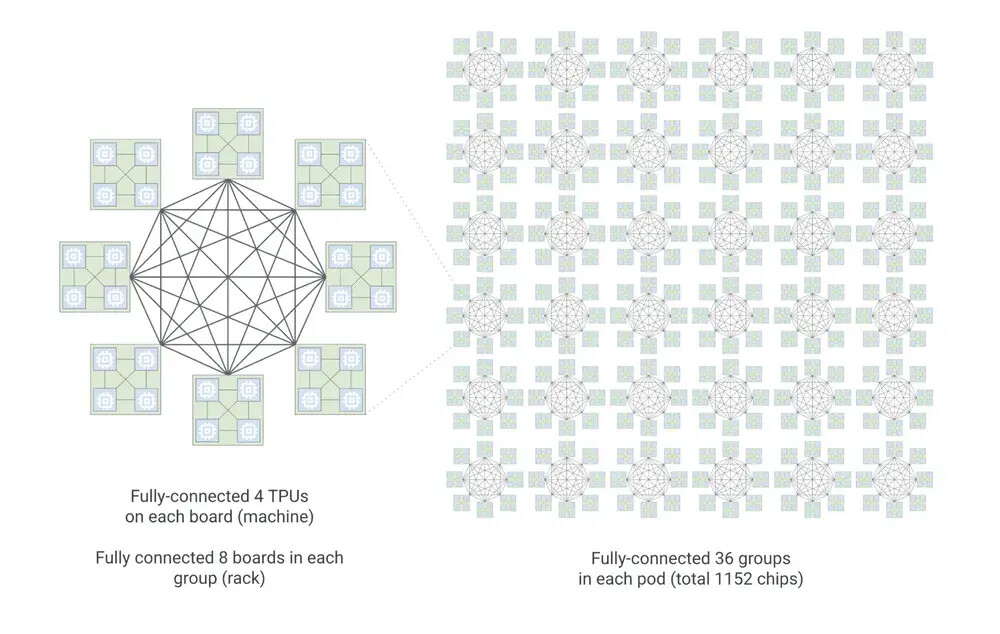
구글의 이원화된 아키텍처는 독자적인 커스텀 슈퍼컴퓨터 인프라를 구축하기 위한 전략적 선택입니다. 학습용 칩은 노드 간 통신 지연을 최소화하는 광회로 스위칭(OCS) 기술과 결합하여 수만 개의 가속기를 단일 시스템처럼 운용할 수 있게 하며, 추론용 칩은 서비스 운영 비용을 획기적으로 절감합니다. 이를 통해 구글은 모델의 탄생부터 실제 서비스 배포에 이르는 전 과정을 수직 계열화하여, 외부 GPU 벤더에 대한 의존도를 낮추고 클라우드 AI 시장에서의 기술적 해자를 구축하고 있습니다.
이러한 하드웨어와 소프트웨어의 긴밀한 통합은 향후 AI 에이전트 기반 산업의 핵심 동력이 될 것입니다.
시사점
구글의 8세대 TPU는 클라우드 서비스 제공사(CSP)가 단순한 서비스 중개자를 넘어 자체 실리콘 설계를 통해 시장의 룰메이커로 진화하고 있음을 보여줍니다. 특히 학습과 추론을 분리한 최적화 전략은 성능 대비 전력 효율(Perf/Watt)이 중요한 데이터 센터 환경에서 강력한 경쟁 우위를 제공할 것이며, 이는 경쟁사들에게 상당한 기술적 압박으로 작용할 전망입니다.


