🔍 핵심 요약
- OpenAI와 엔비디아, AMD, 인텔, MS, 브로드컴 간의 차세대 네트워킹 표준 MRC 개발 협력
- 대규모 GPU 클러스터의 '테일 레이턴시(Tail Latency)' 감소 및 하드웨어 결함 시 자동 복구 기능 강화
- 소프트웨어 중심의 하드웨어 표준 설정을 통한 AI 인프라 운영 비용 및 학습 효율성 혁신
상세 분석
대규모 AI 학습의 숨은 복병: 네트워킹 병목과 신뢰성 문제
현대적 대규모 언어 모델(LLM) 학습 환경에서 가장 큰 비용 손실을 초래하는 요인은 GPU 자체의 성능 부족이 아닌, 수만 개의 칩이 데이터를 주고받는 과정에서 발생하는 ‘네트워크 병목’과 ‘하드웨어 불안정성’입니다. OpenAI는 이러한 문제를 해결하기 위해 엔비디아(Nvidia), AMD, 인텔(Intel), 마이크로소프트(Microsoft), 브로드컴(Broadcom) 등 글로벌 반도체 및 클라우드 리더들과 손잡고 MRC(Memory-Reliability-Communication) 프로토콜 개발을 주도하고 있습니다. 이 프로토콜은 학습 중 단 하나의 GPU 노드에서만 지연이 발생해도 전체 시스템이 멈추는 ‘스트래글러(Straggler)’ 현상을 방지하고, 데이터 전송의 신뢰성을 획기적으로 높이는 데 초점을 맞추고 있습니다.
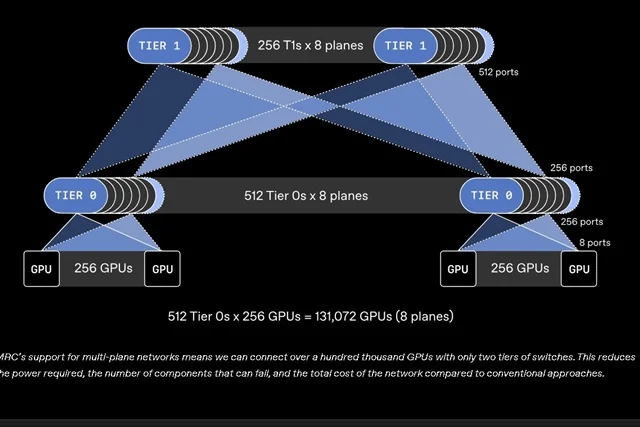
MRC 프로토콜: InfiniBand를 넘어선 새로운 표준의 지향점
현재 대규모 AI 클러스터는 엔비디아의 인피니밴드(InfiniBand)나 RoCE(RDMA over Converged Ethernet)에 의존하고 있습니다. 하지만 OpenAI가 주도하는 MRC 프로토콜은 AI 학습에 특화된 전용 패킷 관리 기술을 도입하여 기존 표준의 한계를 극복하고자 합니다. 특히, 학습 데이터의 집합 연산(Collective Communication)에서 발생하는 테일 레이턴시(Tail Latency)를 최소화하고, 네트워크 전반에 걸친 혼잡 제어(Congestion Control)를 소프트웨어 레벨에서 직접 제어할 수 있도록 설계되었습니다.
이는 하드웨어 제조사마다 제각각이었던 통신 방식을 통합하여, 다양한 제조사의 칩이 혼용된 클러스터에서도 최적의 성능을 보장할 수 있는 환경을 구축하는 것을 의미합니다.
소프트웨어가 하드웨어를 정의하는 시대
MRC 프로토콜의 등장은 AI 산업의 주도권이 하드웨어 공급자에서 소프트웨어 알고리즘 운영자로 이동하고 있음을 보여주는 결정적 증거입니다. OpenAI와 같은 대형 모델 운영자가 자신들의 워크로드에 최적화된 하드웨어 통신 규약을 직접 요구하고, 글로벌 칩메이커들이 이에 동참하는 것은 이례적인 현상입니다. 이러한 협력 체계는 향후 AI 인프라 구축의 표준이 될 것이며, 하드웨어 성능 경쟁을 넘어 시스템 차원의 가동 시간(Uptime)과 안정성이 핵심 경쟁 지표가 되는 새로운 시대를 열 것으로 전망됩니다.
시사점
OpenAI가 MRC 프로토콜을 통해 하드웨어 네트워킹 표준을 주도하려는 것은 엔비디아의 독점적 인프라 생태계에 균열을 내고, 자신들의 인프라 효율성을 극대화하려는 고도의 전략입니다. 하드웨어 제조사들이 이 프로토콜에 참여하는 것은 결국 거대 AI 모델 운영자가 인프라 구매력뿐만 아니라 기술 표준 설정 권한까지 확보했음을 인정하는 결과입니다.


